
画像生成AIは人間の感性に近いアウトプットができるのか?

ChatGPTと時を同じくして話題となっている自動画像生成AI。
今回は3つの画像生成AI「Midjourney*1」「Adobe Firefly*2」「Stable Diffusion*3」に同じプロンプトを入力し、それぞれから出力される画像を比較してみます。果たして、画像生成AIは人間の感性に近いアウトプットができるのでしょうか?
私たち人間がイメージする「シンプル」と画像生成AIが生成する「シンプル」は全く同じものでしょうか?
今回の入力するプロンプトでは共通の認識が存在する固有名詞(車、絵画、帽子など)の使用を避け、抽象的なキーワードを入力しています。これにより、人間が思いつかない造形を生み出せるのかを検証します。
*1 Midjourney: Midjourneyが制作したテキストの説明文から画像を作成する独自の人工知能プログラム。
*2 Adobe Firefly:アドビが制作した、いくつかの言葉やスケッチから、オリジナルのベクター、ブラシ、テクスチャーを生成できる画像生成AI。作成したものはアドビツールを使って編集できる。Adobe Stockの中から著作権者がAIの学習データに使用することを許諾した画像・オープンライセンス作品・著作権期限切れのコンテンツのみを学習データに活用している。
*3 Stable Diffusion:Stability AIが制作したStable Diffusion 画像生成モデルを使用して画像を作成するための使いやすいインターフェース。画像生成に加え、スケッチを読み込ませて清書を行う機能がある。
比較するプロンプト(2種類)
今回は、入力するプロンプトを2種類設定して、出力した画像を比較します。
比較する2つのプロンプトはこちら。
プロンプト① modern, composure, soft, cool, stately, monochrome, geometric pattern
(モダン × 落ち着いた × 柔らかい × 涼しげ × 重厚)+(モ ノクロ × 幾何学的な柄)
プロンプト② classic, gaudy, hard, warmth, light, monochrome, geometric pattern
(クラシック × 派手な × 固い × 温かみ × 軽やか)+(モノクロ × 幾何学的な柄)
それぞれのプロンプトには、対となる抽象的なキーワードを設定しています。たとえば、プロンプト①には「modern(モダン)」、プロンプト②には「classic(クラシック)」。プロンプト①には「 composure(落ち着いた)」、プロンプト②には「gaudy(派手な)」というキーワードが入っています。
この対となるキーワードは、普段 Balloon Inc. でシンボル・ロゴを開発する際に使用しているイメージ調査票項目をベースにしました。以下はご依頼いただいたデザインのイメージをお伺いするときに使用しているものです。

温かみや涼しげといった項目は画像全体の色使いによって比較的容易に生成されるため、「monochrome(モノクロ)」というキーワードを追加しています。
また、対となるキーワードの他に「monochrome(モノクロ)」、「geometric pattern(幾何学的な柄)」をそれぞれの末尾に追加しています。
現実に存在するオブジェクト(車や家具、衣装など)が含まれた場合、それらの具象的な造形によって抽象度の高いキーワードの表現が可能と捉え、「geometric pattern(幾何学的な柄)」を加えることで、抽象的な画像出力をめざしています。
生成画像の比較
プロンプト① modern, composure, soft, cool, stately, monochrome, geometric pattern
【Midjourney】

②の画像は唯一グラデーションが使われていないことから、プロンプトに対しての出力がワンパターンではなく様々アプローチからイメージを出力しようとしていることがわかります。
例えば、「高級感=グラデーション」といったような固定観念をもって制作をしてしまう事がありますが、ここでは固定観念を持たずにイメージを出力するMidjourneyの思考の柔軟性を感じました。
①は図形の重ね方と、ハイライトの当たり方によって底知れないような暗さがあり違和感のない奥行きのある幾何学図形になっています。全体的に明暗がはっきりしているので暗い部分の重厚感がより感じられる画像です。
【Adobe Firefly】
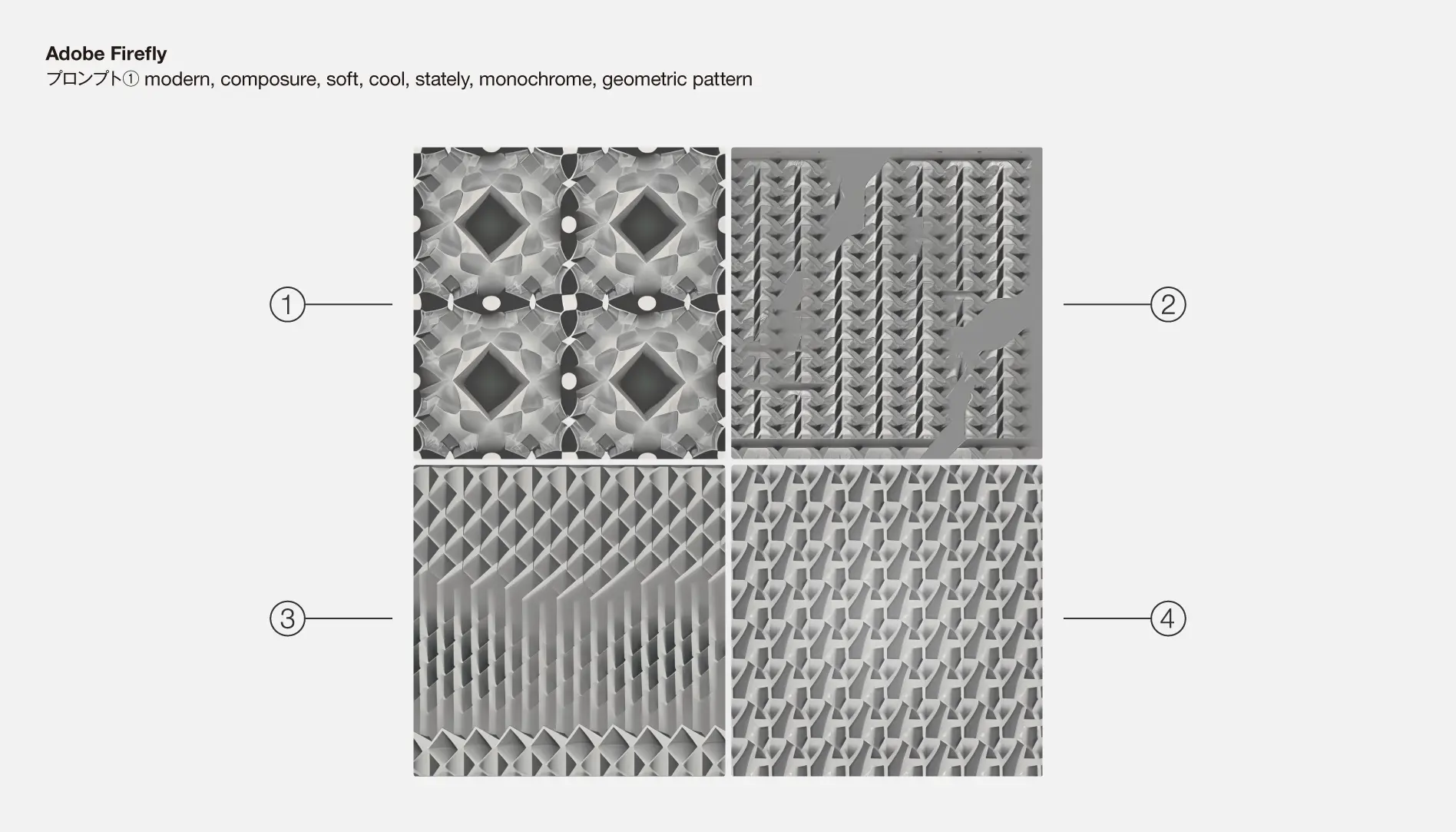
②と③の画像は、所々ガウスがかかっていて、落ち着いた雰囲気を感じます。
全体の印象は同じ幾何学系が繰り返されていて、複雑さのない比較的シンプルなパターンになっています。また、③の画像には不規則にに不自然な形が混ざっていて、入力したプロンプトのキーワードを上手く融合できなかったように感じられます。
【Hugging Face (Stable Diffusion)】

インテリアの無駄を削ぎ落とした、シンプルでスタイリッシュな空間デザインです。④以外の画像は入力したイメージに近い画像になったように見えます。
④の画像には、家具の脚がロココ様式の「カブリオールレッグ」に見えるほか、装飾的なシャンデリアや中世ヨーロッパ時代の様式の額縁(と絵画)が飾られています。このことから、この画像だけがクラシカルな空間になっています。
他のプロンプト(soft, cool, stately)の影響で「モダン」とは正反対なクラシカル要素が混入したのではと推測されます。指定したキーワードとは逆の特徴が生成画像に出てしまっていて、めざすイメージからかけ離れます。
プロンプト② classic, gaudy, hard, warmth, light, monochrome, geometric pattern
【Midjourney】

②の画像以外は宝石のカットを思わせる立体形が多く、その陰影の付け方やハイライトによって光っているような表現になっていて、派手できらびやかな印象を受けます。
①と②の画像は特にカーブが多く、柔らかく優しいリラックスした雰囲気を感じさせます。どの画像にも角張った立体図形と、半円や波線などのカーブのある図形が共存していて、緊張と緩和を感じることができます。
【Adobe Firefly】

③の画像は、古代ギリシア古典期の建築様式であるコリント式の柱のようなシルエットを想起させます。植物や蔓を図案化した装飾がほどこされているので、華麗さや繊細さを感じました。
しかし、それ以外の3つの画像はさきほどの「プロンプト①modern, composure, soft, cool, stately, monochrome, geometric pattern」と大差ない印象です。
【Hugging Face (Stable Diffusion)】

②と③の画像にあるシャンデリアや大きな絵画、全ての画像に共通する椅子や机のデザインが、古代ローマや古代ギリシアの造形を思わせます。そのため全ての画像にクラシックな雰囲気を感じました。
①のソファにあるクッションの柄(文字)の「u」のディティールには、11-12世紀のヨーロッパで作られたBlackletter書体のRotundaに近いディティールがあり、その他の文字にはセリフ書体の特徴も含んでいることが見受けられます。
比較した感想
同じプロンプトを用いて生成した場合、Midjourneyは平面的なパターン、Adobe Fireflyはグラデーションのある立体的な柄、Hugging Face(Stable Diffusion)はインテリアや空間といった、アウトプットの形式に広くばらつきがありました。
そのため、各サービス同士の生成画像の比較が困難だったというのが正直なところです。サービスによって自動生成の質が高いジャンルがあるのではないかと推測されます。それを理解した上で用途に応じて使い分けることで、画像生成AIをより有効に活用できそうです。
Balloon Inc. では、ブランド戦略の立案から実施運営まで、初期段階から一貫してサポートしています。ブランディングをはじめプロダクト・グラフィックデザインなど幅広い領域で伴走支援が可能です。お気軽にお問い合わせください。

ご相談・お問い合わせ
貴社のブランド構築や課題解決にも、私たちBalloon Inc.のデザイン専門知識を役立ててみませんか?




